Prometheus, Grafana, rates, and statistical kerfluffery
I love performance graphs and monitoring software; graphs are pretty, and there's nothing quite like the feeling of using a graph to identify precisely the cause of a technical problem. It means, however, that every few years I end up delving deep into some aspect of them to figure out why my graphs don't look 'right'. A few years ago it was Cacti + RRD losing information we thought we were keeping (pro-tip: consolidating to the maximum value of an average seen over a given period, rather than keeping the maximum of all maximums seen, is probably not what you want). This is the store of my latest battle with Prometheus and Grafana; there are quite a few different moving parts involved, and the story is an interesting one. Come on a journey with me (Spoiler: I win in the end).
I am in the early stages of a Prometheus + Grafana deployment for my current employer. Set up was pretty easy, and things generally worked, but it quickly became apparent that certain graphs were 'jumpy'. CPU usage was an obvious one, so was some of the disk I/O graphs; others were rock solid. By 'jumpy' I mean that as the graph updated (every 10 seconds by default in the Grafana interface), spikes would change size or even disappear entirely before reappearing an update or two later:
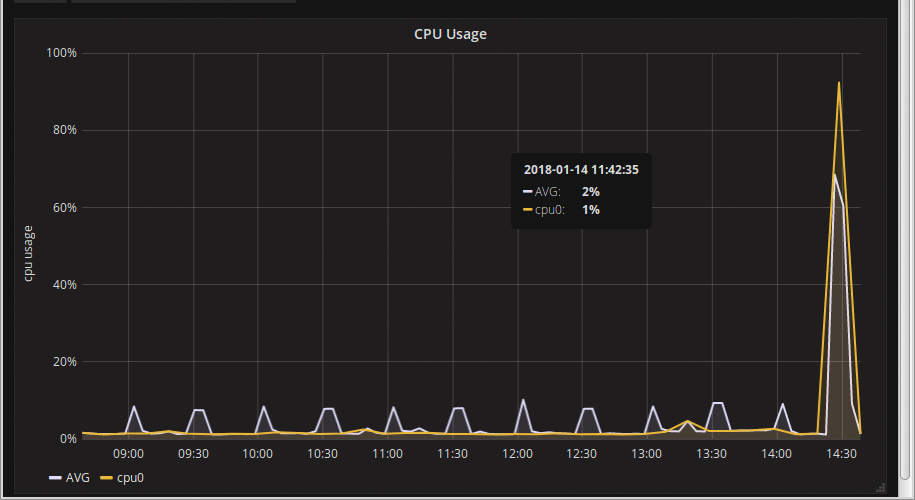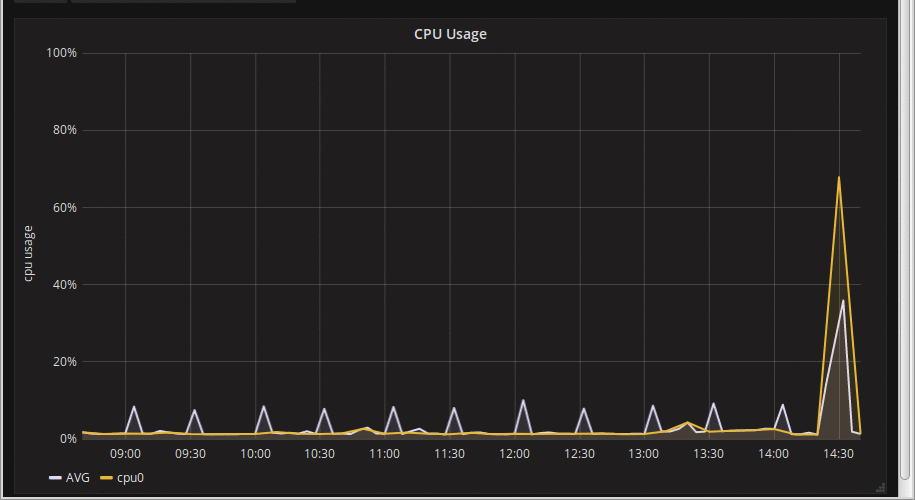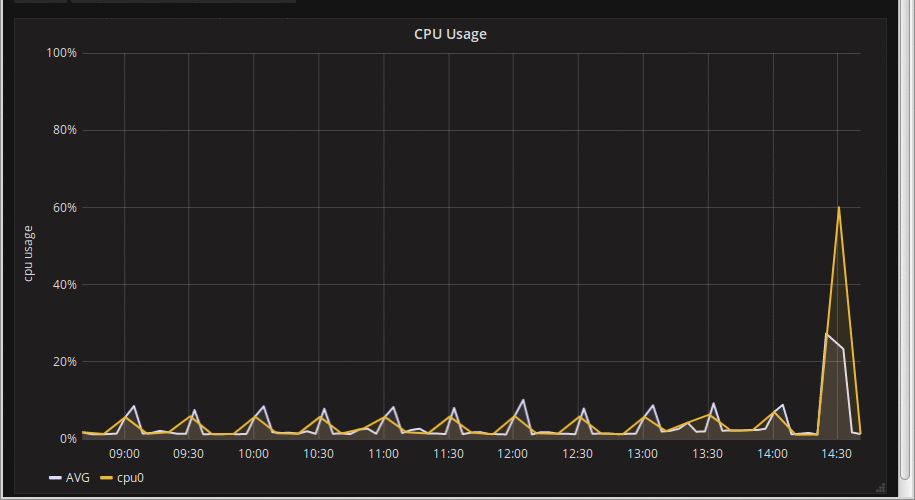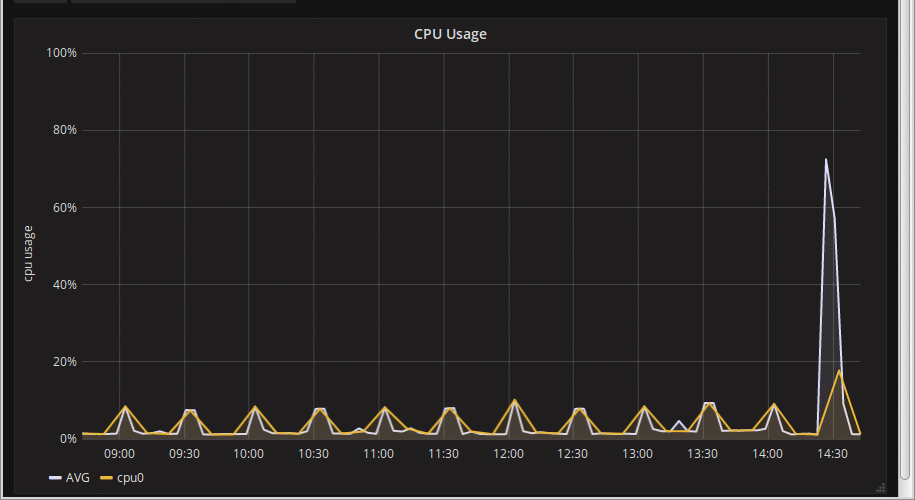
What the hell is going on? Some internet searches later, and this is appears to be a fairly common problem. After delving further into it (web-browser debug console FTW, amirite?), this issue is one of sub-sampling on rate-based expressions. Grafana tries very very hard not to request more detail than it can show on the screen, presumably on the grounds that fetching more datapoints than you have pixels is mostly pointless (pun not intended, but I like it, so it stays). To achieve this, it passes a 'step' in the query to Prometheus (e.g. 40seconds). Prometheus then starts at the 'from' timestamp, calculates a rate-of-change over the 'interval' specified in the rate expression, i.e. from -> from + interval. It then increments the timestamp by the *step* to get the next data point, repeating until it gets to the 'to' timestamp[1]. If the interval given to 'rate' is shorter than the step, you end up getting a moving sub-sample of the raw data. As you can see in the graph animation above, there was a definitely spike around 14:30, but as we sample different sub-period we end up not sampling data from the full spike. In this case the rate expression was calculating a rate over 5 minutes (300 seconds), but the step being used by Grafana at this resolution was 1200s (20 minutes). A simple visualisation may help:
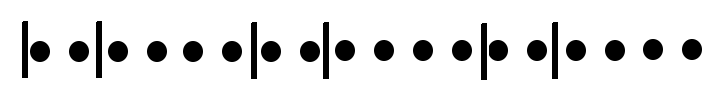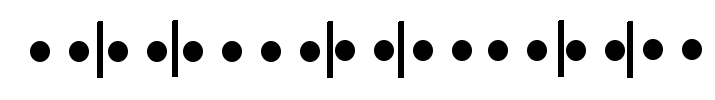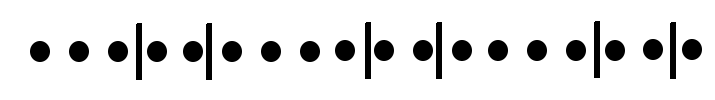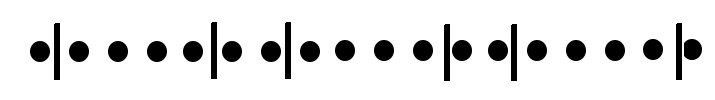
This is not terribly useful. There is an easy fix though: rather than hard-coding an interval in the rate expression (e.g. 5m, 10s), use $__interval ($interval in Grafana < 4.2), e.g.: rate(cpu{mode!="idle"}[$__interval]). This ensures that the step chosen by Grafana will be used by Prometheus when calculating the rate; the data returned will get a full view of the data between 'from' and 'to', to the resolution of the graph currently being displayed. NB: At low zooms (high step/interval) fine detail will less visible, e.g. a very short + large spike will be smoothed out/reduced, but this is an inevitable situation.
So I did this, and my graphs looked much more stable, and I went on annual leave very pleased with myself. Then I came back, and started working on it again, and noticed that while *mostly* stable, the graphs were still around a bit:
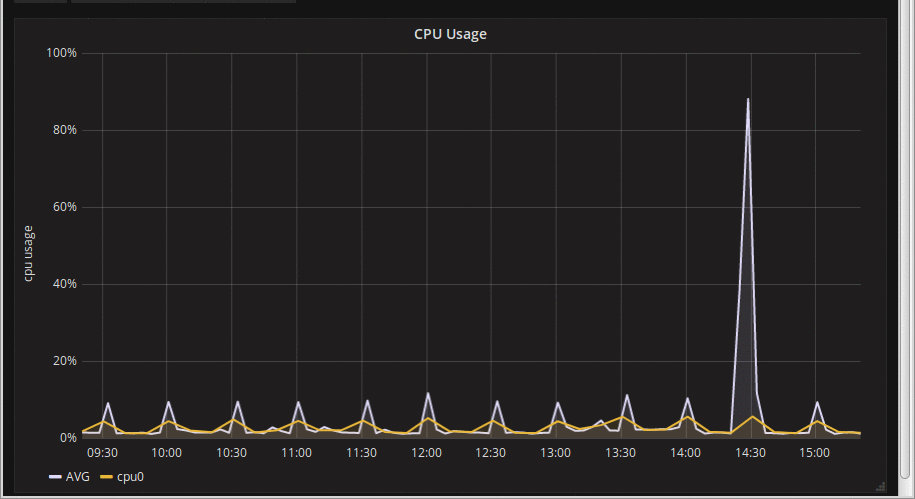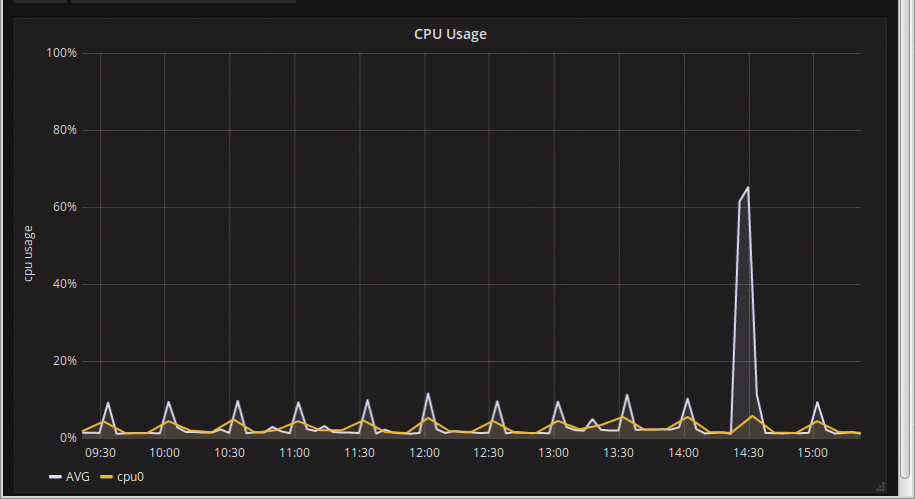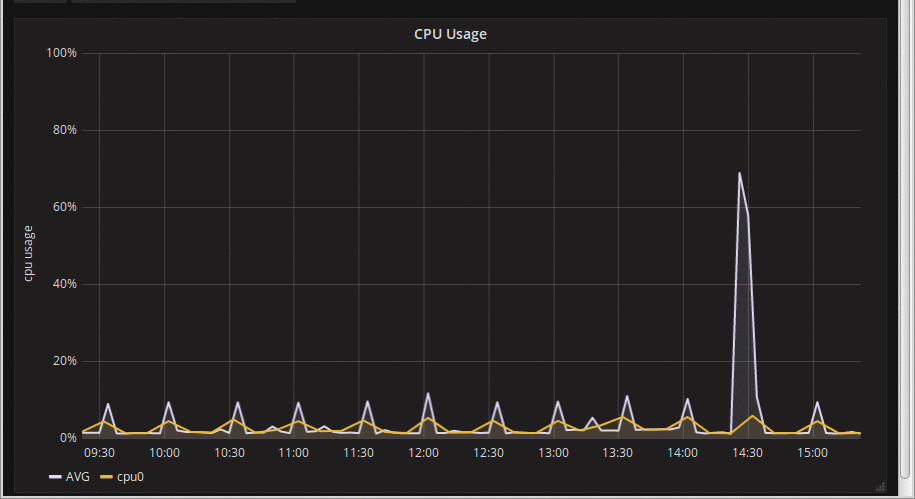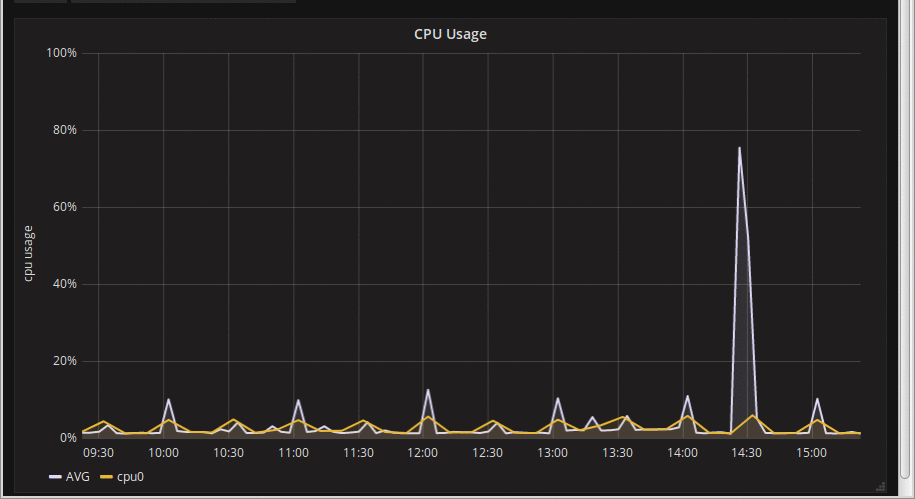
What the hell is going on now? Using the web browser debug console again, it quickly became obvious that the issue was a *moving* window. Grafana was using the step as $__interval properly, but the 'from' & 'to' timestamps were not aligned to the step; every time the graph updated, the time window would move a bit to the right by a few seconds, and the rates would be calculated over a different interval. The data is all there, but it's was being summarised differently (sometimes making the spike wider and longer, sometimes shorter and taller. The overall pattern would be largely retained but there was variability. This demo animation hopefully shows what's going on:

The solution here was to patch the Prometheus datasource plugin in Grafana to align the 'from' & 'to' timestamps to integer multiples of 'step' ( extending the range if required and thus potentially adding 1 or 2 more datapoints, which is a very small price to pay). This took a while; the trivial implementation had a few issues that broke the CI tests, and required a slightly more complex solution. But in the end, it worked. And now my graphs are stable.
I submitted a PR for exactly this (https://github.com/grafana/grafana/pull/10434) but this has (re-)triggered wider discussions about how to deal with this, so it might be a while before it lands.
So everything is fine, right?
No, no it's not. Not by a long way. I finally installed Prometheus and and un-patched Grafana to monitor my personal server (which hosts this site), in part to help get some data for this post. Then I saw some odd looking network spikes and wanted to see more, so I added some dirty hacky metrics (added via a cron job writing to a file in the dir that node_exporter looks for textfiles with metrics in), derived from the packet/byte counts of some custom iptables rules. The data for some of the rules has a very low and bursty rate of change, and when I was viewing the graphs, they would look fine for a bit, then as the time window shifted, whole sections of the graph would go to 0 where they had a non-zero rate before. Eventually the time window would shift again and the graph would spring back to life.
Had I misunderstood what Grafana was doing? I understand the moving window problem, so I was expecting the graph to jiggle around a bit, but that shouldn't cause whole sections to drop to 0. I was flummoxed. Back to the web console I went, and eventually to using curl. It still made no sense. If I shifted the start/end of the query by 1 second I could go from a series of vaguely sensible rates to a series of zeroes. If I didn't use rate, and used a step of 1, I could see the literal stored values were doing what I expected of them. Eventually I grabbed the prometheus code, and added a bunch of fmt.Printf statements into the rate function (yay, my first Go programming!). The scales fell from my eyes, and I was enlightened.
The rate function uses the rate interval to extract subsets of samples, as we've previously determined. With a rate interval of 60 seconds, and an original scrape interval of 15 seconds, it would look at sets of 4 samples at a time. It has to do an extrapolation, because strictly speaking, 4 samples covers a 45 second interval (3 gaps of 15 seconds each, another manifestation of the 'number of fenceposts' problem). It does this by assuming that the rate of change over the 45 seconds would extend to the full 60 seconds. The trouble comes when our step is also 60 seconds. Consider the set of samples:
1 2 3 4 4 4 4 6 6 6 6 9 10 12 13
We'll deal only with deltas, because it keeps the math simpler, but it's all the same as a rate is proportional to the delta (divided by the window length (60s) to get a rate per second). If we start at the left-most, our first window is 1 2 3 4, which generates a delta of (4-1)*60/45, or 4. Which is not a bad guess, because the metric is going up by 1 every 15 seconds. The second window is 4 4 4 6, which comes out as 2*60/45, or 2.666. Again, not a terrible guess. The next window is, 6 6 6 9 which comes out to a delta of 4. So far, so good; the graph of the delta will be 4 2.666 4.
But what happens when the window moves to the right? 45 seconds after the first graph, the first window now contains four sequential 4s. The unextrapolated delta (and thus rate) is 0, and no amount of multiplying will give a higher number. The graph will suddenly drop to 0. Worse, the next window of 6 6 6 6 also generates a delta and rate of 0. We've lost the fact that the metric rose from 4 to 6 between the two windows, and generated two result rates of 0 when reasonable results would be either '1' for both, or 0 and 2, in that order. The very thing the extrapolation is trying to solve is broken by the pathological data we've thrown at it (sets of samples with zero delta across exactly a window of the rate interval).
The fundamental problem is the step being the same as the rate interval. If, however, the rate interval is longer than the step by at least one scrape interval, then the windows overlap by one sample each time, e.g. if we reduce the step to 45s, we see the following sample sets: 1 2 3 4, 4 4 4 4, 4 6 6 6, 6 6 9 10, and we don't lose the delta in between the windows anymore. Having gone through the code, I'm of the opinion that Prometheus is doing the right thing given the exposed API of rate interval and step, and the fix needs to be in the client.
The corollary is that my solution of using $__interval for the rate interval is, while on the right track, slightly harmful in pathological cases. The from & to still need to be aligned to a multiple of step to avoid the moving window problem, but we need to also increase $__interval by the Prometheus scrape interval (somehow). This might prove to be tricky, and I don't know there's going to be a good solution, other than some dirty hack in the Prometheus data source in Grafana.
Why doesn't this happen in other tools?
There are a couple of key reasons:
- Prometheus doesn't store rates; it calculates them only when requested in a query. Compare this to RRD (https://oss.oetiker.ch/rrdtool/doc/rrdcreate.en.html#IIt_s_always_a_Rate) which takes counter-type data values and calculates the rate as they are received. Prometheus has a much more fluid view of the world; RRD expects updates at known frequency (and coerces/aggregates the received data points to those known intervals), but the TSDB in Prometheus doesn't expect anything and just deals with exactly what it gets (timestamp + datapoint + labels). It is possible to use Recording Rules to calculate and store rates, but that would typically be an aggregation, not the original raw data.
- Rate calculation requires an interval, and because Prometheus is doing it on the fly at query time, the query needs to supply the interval. It's at this point that Grafana starts to have the observed difficulties.
In some respects, Prometheus does all this better because it keeps the raw data for longer; by not consolidating early, we retain the ability to find the peaks (e.g. the max_over_time function). RRD demands we determine our consolidation functions early. Mind you, RRD is predicated on long term consolidation/storage, where Prometheus isn't (by design). https://www.robustperception.io/how-does-a-prometheus-counter-work/ is, although slightly tangential, well worth a read (as is anything on the Robust Perception blog).
Aside about 'irate'
What about the 'irate' function in Prometheus? It's worth noting that irate is a very very special function in Prometheus; instead of looking at the entire given interval, it looks exclusively at the last two values in the interval, and calculates a rate based on them alone. It intentionally throws away a lot of information. I'm not convinced I understand the meaning of the documentation which suggests it should be used for volatile fast-moving counters; to my way of thinking, if it's volatile you want to use rate to get a more accurate view over time, and zoom in if you need to see local details. Consequently, I strongly suggest you use rate as a matter of habit, and only use irate if you truly know what you're doing and that you need to see instantaneous rates only. Using it where you should be using 'rate' will lead to the original symptoms (sub-sampling), unless your step is 2 times the original sample interval, or less, and there's nothing grafana (or anything else) can do to make that Prometheus query return wider data. If you're downloading grafana dashboards, double check them to see if they're using irate.
Conclusion
Stats is hard, and if you don't understand what data is actually being manipulated, you can end up with some very strange results.
Addendum, 4 days later
Someone else has done the exact same investigation as me, and reported to Prometheus, in the last week or so. Great minds etc... :) https://github.com/prometheus/prometheus/issues/3746 and https://github.com/prometheus/prometheus/pull/3760
[1] It may, based on a comment I saw in IRC, start at 'to' and work backwards, but even if so, it's not substantively different than the other direction, and is slightly harder to explain, so forgive me my simplification.